Build AI Code Generation Tools For Large Scale Project in Python? Part 2 - Development Diary and Discussion
Building AI Code Generation Tools from Scratch in Python 3: A Journey from Zero to Everything (Part 2)
If you missed Part 1, you can find it here: link. In our previous discussion, we covered the basic workflow, fundamental code generation, directory creation, file generation, and folder automation.

Disclaimer:
I won't be sharing the complete project code directly. Instead, I want to foster discussion and collaboration.
- For Beginners: Use this as a guide to build your own project and join the conversation. I'm happy to help with any learning challenges you encounter.
- For Experienced Developers: Please share your insights and discuss potential improvements.
Our journey doesn't end here. In this part, we'll delve into some of the challenges we've faced in previous part.
Challenges:
- Token exhaustion: Large files exceeding token limits.
- Code skipping: The LLM omitting parts of the implementation.
- Inconsistent code generation: Function naming inconsistencies across files.
Token Exhaustion
What are tokens?
Tokens are the building blocks of text for large language models (LLMs). They can be words, character sets, or combinations of words and punctuation. (Definition from Microsoft). If you have a basic understanding of how computers represent characters (like ASCII or other encoding systems), you'll know that text is ultimately converted into numbers for processing. As LLMs perform calculations (as discussed in my blog, "The AI Boom: Why Is Everyone Talking About It?"), these tokens, or pieces of text, must be represented numerically. The output is also numerical, which is then translated back into the text we see.
Why do tokens matter?
The computational capacity of an AI model limits the input and output size, defining the maximum amount of text it can handle. This constraint is inherent to the model. When using APIs like Claude or Gemini, you'll encounter limits on file size, token count, or context window. These are limitations we can't directly overcome. So, how can we manage them?
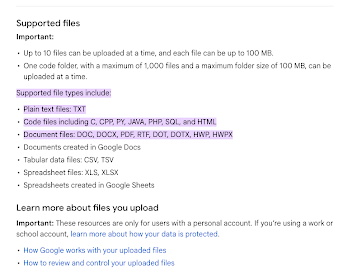
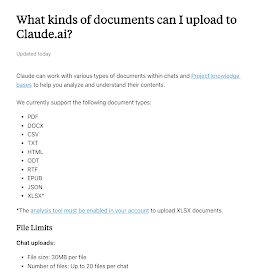
For input, we can use a technique called "chunking."
Why do we need input? Imagine you have extensive documentation or requirements from various sources. These can serve as input for generating your code requirements, or understanding existing code base.
Chunking involves estimating the token count of your input. If it exceeds the limit, we instruct the model to summarize the content. To illustrate, think of packing a moving truck. We disassemble furniture, categorize items, and load them efficiently. Similarly, chunking involves summarizing large chunks of text and combining those summaries into the final prompt for generating the desired output.


For output, we'll discuss this alongside code skipping.
Code Skipping
We can try to improve the prompt by explicitly telling the model not to skip code. However, we may still encounter the token exhaustion problem.

I've considered three approaches:
- Generate an initial code layout, then generate the body of each function separately.
- Generate initial code and use a Git diff-like approach to add or remove content.
- Generate initial code and add a marker to indicate where the model should continue if it doesn't finish. (Basically the same as 1, but just different approaches)
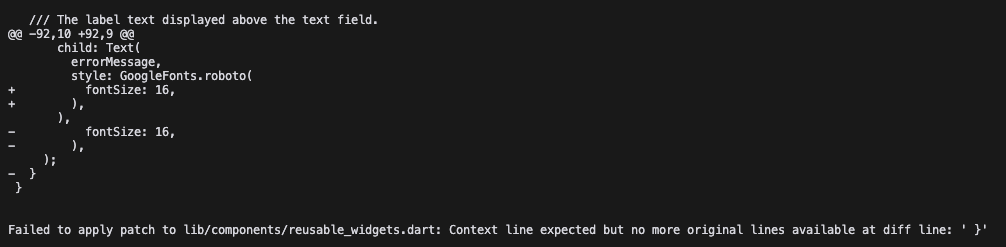
These methods are still being tested. However, it's clear that the Git diff approach doesn't yield good results.
It's likely that LLMs aren't extensively trained on Git diff workflows. So we could ignore approach 2
Inconsistent Code Generation
Since we've defined the file structure and descriptions, we can include this information in the prompt during code generation. Alternatively, we can address inconsistencies during a compilation phase. This compilation phase will handle various errors and fine-tune the code, avoiding duplication of effort during generation.
What's now
Parts 1 and 2 have successfully created a basic code generation framework, establishing a project structure. The challenge now is that the generated code is unusable, filled with syntax errors and making no logical sense.
Next Steps:
I plan to discuss how to implement an initial compilation process to overcome the initial generation problem and compilation challenges.
Stay tuned! I welcome all comments and thoughts on this implementation. Please leave a comment so we can discuss further.
By the way, I'm not sure how many parts this blog series will have. If you're interested, please show your support by sharing or commenting!




Comments
Post a Comment